
ChatGLM-6B是一个基于General Language Model (GLM)架构的开源对话语言模型,支持中英双语。该模型使用了和ChatGPT类似的技术进行优化,经过1T标识符的中英双语训练,同时辅以监督微调、反馈自助和人类反馈强化学习等技术,共有62亿参数。
ChatGLM-6B由清华大学 KEG 实验室和智谱AI共同开发,通过模型量化技术,用户可以在消费级显卡上进行本地部署(INT4量化级别下最低只需6GB显存)。
ChatGLM-6B可以简单的理解为本地私有部署的弱化版ChatGPT。
经过多次尝试,xiaoz终于成功地在Windows 10上运行了ChatGLM-6B对话语言模型。在此记录并分享整个过程。

阅读基础
本文适合对人工智能感兴趣的研究人员阅读,需要一定的编程基础和计算机基础。如果您熟悉Python编程语言,那就更能够更好地理解本文。
硬件 & 软件准备
ChatGLM-6B对软硬件都有一定的要求,以下是xiaoz的硬件信息:
- CPU:AMD 3600
- 内存:DDR4 16GB
- 显卡:RTX 3050(8GB)
软件环境:
- 操作系统:Windows 10,也可以是其它操作系统
- 安装Git工具
- 安装Python,我的版本为
3.10 - 安装英伟达驱动程序
这篇文章假设您有具有一定的编程基础和计算机基础,因此并不会详细介绍上述软件工具的安装和使用,如果您对此并不熟悉,建议直接放弃阅读。
部署ChatGLM-6B
ChatGLM-6B已在Github开源:https://github.com/THUDM/ChatGLM-6B
首先需要使用Git克隆代码:
git clone https://github.com/THUDM/ChatGLM-6B.git接下来我将pip设置为了阿里镜像源,方便我之后的步骤能更顺利的安装Python各种依赖库,命令为:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
pip config set install.trusted-host mirrors.aliyun.com然后进入ChatGLM-6B目录,在命令行安装Python需要的依赖,执行命令:
pip install -r requirements.txt接下来是下载模型,由于xiaoz的显卡比较弱,所以xiaoz这里选择了 4-bit量化模型,建议提前下载好模型,内置的Python脚本下载很容易失败,且速度较慢。
作者将模型托管在“Hugging Face Hub”,我们需要先从上面下载模型,xiaoz这里选择的“4-bit量化模型”,执行的命令如下:
git clone -b int4 https://huggingface.co/THUDM/chatglm-6b.git这里面pytorch_model.bin文件比较大,如果您git命令拉取较慢,或者失败了,可以尝试手动下载pytorch_model.bin,然后放到本地仓库目录即可。
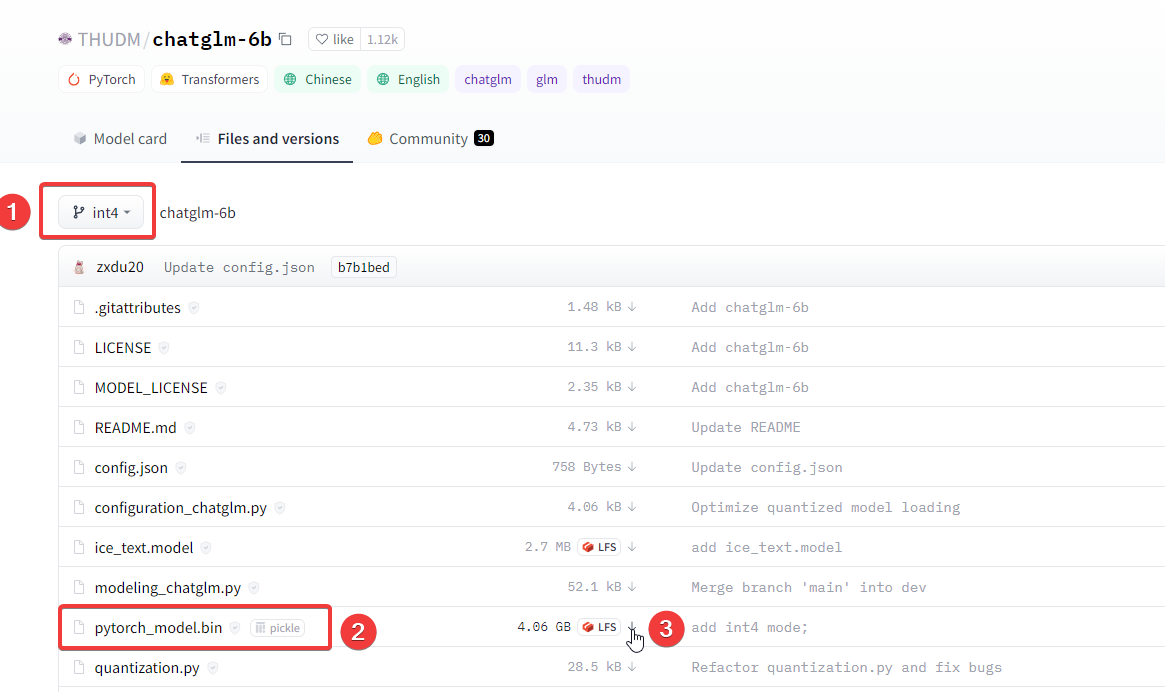
注意:这里存在一个坑,你不能只下载.bin文件,需要将里面的.json/.py等文件一起下载并放到一个目录,建议是Git拉取整个仓库,然后手动下载.bin合并到一个文件夹下。
运行ChatGLM-6B
进入Python终端,我们开始运行ChatGLM-6B模型,执行的命令如下:
# 指定模型的位置,就是你在Hugging Face Hub上克隆下来那个模型
mypath="D:/apps\ChatGLM-6B\model\int4\chatglm-6b"
# 导入依赖
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained(mypath, trust_remote_code=True)
model = AutoModel.from_pretrained(mypath, trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)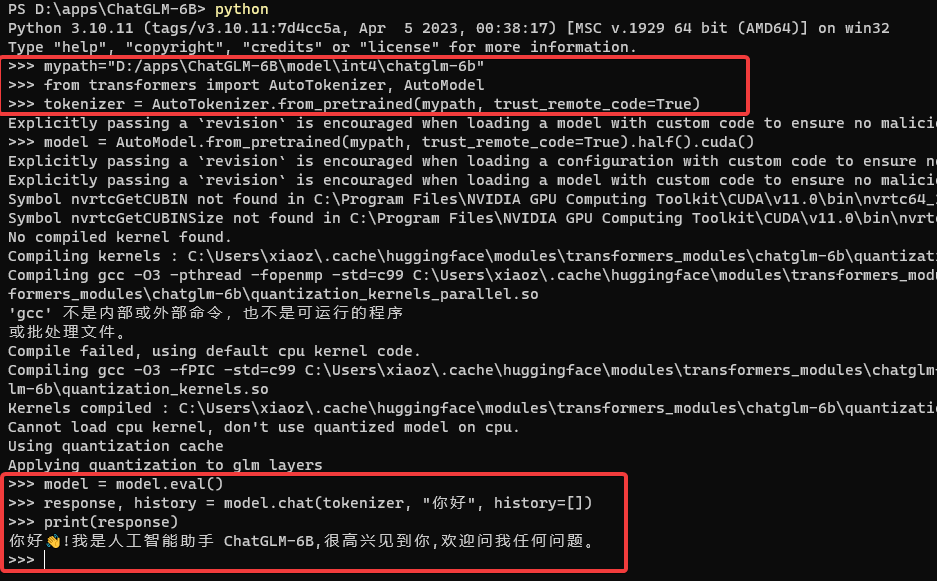
运行过程中,并非我想象中的那么顺利,我遇到了一个
Torch not compiled with CUDA enabled
这样的报错,最后参考这个:issues 解决了。
解决办法是先执行命令:
python -c "import torch; print(torch.cuda.is_available())"如果返回False,说明安装的PyTorch不支持CUDA,然后xiaoz执行了下面的命令:
pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 -f https://download.pytorch.org/whl/cu118/torch_stable.html最后就没报错了。当然,每个人的硬件和软件都不一样,遇到的报错可能也不一样,总之灵活变通就行了。
命令行测试ChatGLM-6B
跑个4-bit量化模型也比较吃力,3050的8G显存很容易给我干爆,而且响应速度感觉也比较慢。(图片可点击放大)
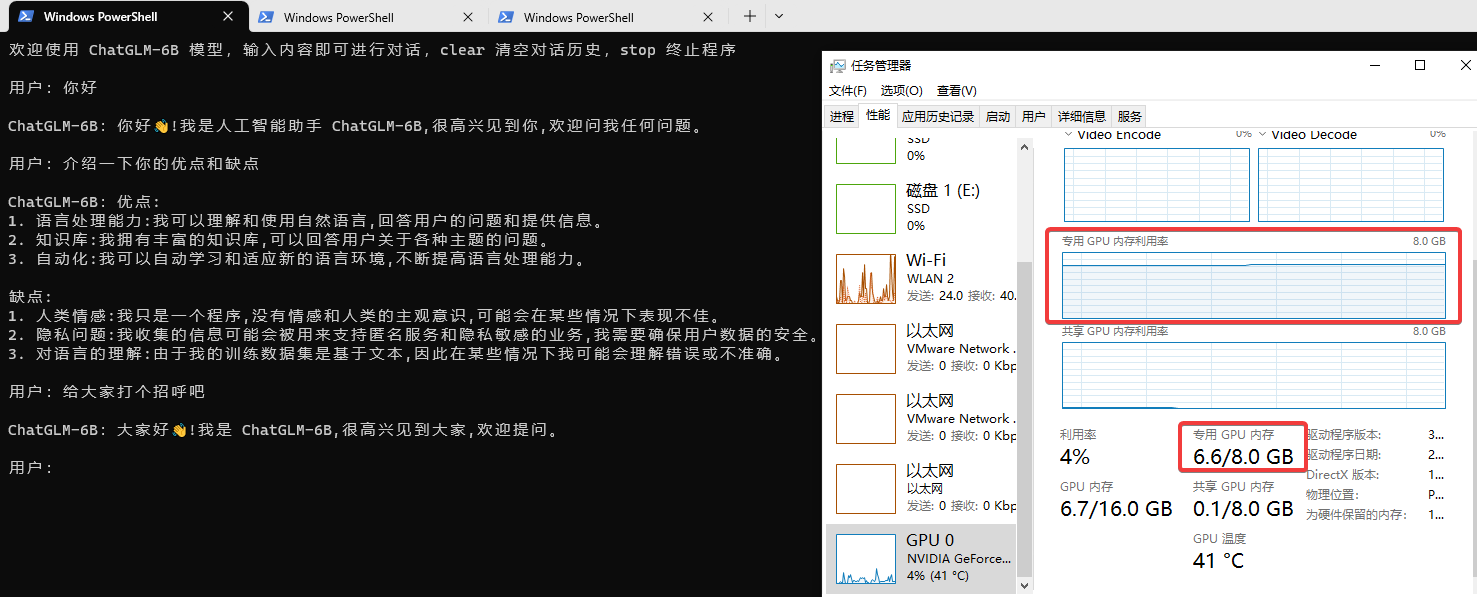
官方仓库里面还提供了WEB和API的运行方式,WEB运行方式遇到点报错,暂时还没去解决,上述使用CLI运行方式是没问题的。
补充说明
要查看自己安装的PyTorch版本,可以在Python交互环境中输入以下代码:
import torch
print(torch.__version__)如果结果显示的x.x.x+cpu可能会导致不支持,参考上面的“Torch not compiled with CUDA enabled”报错解决即可。
再次查看 PyTorch 版本,若显示+cuxxx,则说明支持 GPU,也就是说不支持 CPU 的+cpu版本不可用,只可用支持 GPU 的+cu版本。
个人感受
我与ChatGLM-6B进行了一些简短的对话,个人感觉效果不错。虽然整体上不如ChatGTP,但ChatGLM-6B由国内开发团队开源,并且可以在消费级显卡上运行,我必须给予好评和点赞。希望团队继续努力,迎头赶上ChatGTP。
ChatGLM-6B开源地址:https://github.com/THUDM/ChatGLM-6B
向大佬致敬~!
不敢当,我只是一个学徒而已。