
最近,百度飞桨平台发布了全新的PP-OCRv6识别模型。它在保持极致轻量的同时,实现了精度与速度的跨越式提升。xiaoz亲测部署后,发现识别效果确实不错,于是将其封装成了一套在线HTTP API调用方案,现正式开源分享给大家。
Zocr开源地址:https://github.com/helloxz/zocr
Zocr特点
我将这套整合方案命名为Zocr,具有以下特点:
- 基于百度飞桨PP-OCRv6识别模型,提供两档可选:tiny / small
- 支持Bearer Token认证
- 支持Docker容器化部署
- 纯CPU推理,不依赖GPU
- 支持常见图片格式:jpg/jpeg/png/bmp/webp
- 支持HTTP调用
- 轻量级占用
Docker Compose部署
创建compose.yaml文件:
services:
zocr:
image: helloz/zocr
container_name: zocr
ports:
- "5080:5080"
environment:
- ZOCR_TOKEN=your_token_here
restart: always注意:请将
your_token_here设置为您自己的密钥,支持字母或数字。
可选环境变量:
ZOCR_WORKERS: uvicorn工作进程数,默认1ZOCR_MODEL_VERSION: OCR模型版本(tiny/small),默认smallZOCR_MAX_FILE_SIZE: 最大文件大小(bytes),默认10485760
启动服务:
# 启动服务
docker compose up -d使用
测试
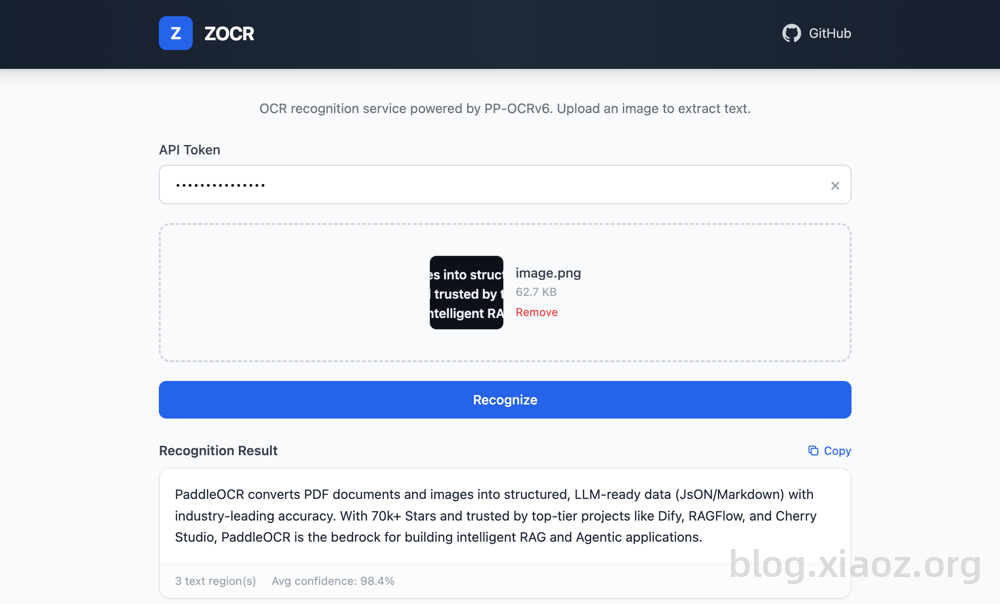
部署完毕后访问:http://IP:5080打开WEBUI,然后填写您刚刚设置的ZOCR_TOKEN,然后上传图片即可自动识别和提取图片中的文字信息。
HTTP API调用
HTTP API支持2种接口,一种是上传文件识别,一种是通过传递图片URL进行识别,调用方法如下:
# 使用curl调用(上传文件)
curl -X POST http://localhost:5080/api/ocr/upload \
-H "Authorization: Bearer your_token" \
-F "file=@test.jpg"
# 使用curl调用(通过URL)
curl "http://localhost:5080/api/ocr/fetch?url=https://example.com/image.jpg" \
-H "Authorization: Bearer your_token"接口响应格式为:
{
"code": 200,
"msg": "success",
"data": {
"texts": ["识别文本1", "识别文本2"],
"scores": [0.99, 0.95],
"boxes": [[[0,0], [100,0], [100,30], [0,30]], ...],
"full_text": "识别文本1\n识别文本2"
}
}结语
Zocr 是xiaoz基于 PP-OCRv6 封装的轻量级 OCR API,支持 Docker 一键部署,CPU 即可高效运行。现已开源,欢迎体验、提 Issue 或贡献代码。如果对您有帮助,不妨给个 Star 支持一下!
Zocr开源地址:https://github.com/helloxz/zocr
基于Aria2的,浏览器插件不都是通用的。
大哥是不是走错片场了,Aria2不是下载工具吗,这个是OCR图片识别文字。。。